주어지는 파일

Position.exe 실행 모습

ReadMe.txt 내용
ReversingKr KeygenMe
Find the Name when the Serial is 76876-77776
This problem has several answers.
Password is ***p
Input name은 알파벳이 들어가고,
Input Serial은 숫자가 들어가나 보다.
문제 분석

참조되는 문자열 목록을 보면 아까 실행 창에서 보였던 Input Name이랑 Input Serial이 보인다.
그리고 그 밑에 Correct! 와 Wrong 문자열이 보인다.
실행되는 모습에서 보이다시피 Wrong이라는 문자열이 Default로 프로그램 하단에 적혀있다.
그럼 비교를 통해서 이 Wrong 부분을 Correct!로 바꿔주는 부분이 있을 것이다.
저 문자열 주소로 이동해 보자.

굉장히 간단하다.
position.AC1740이라는 함수의 리턴 값으로 Correct!나 Wrong 문자열이 결정된다.
이 함수에 bp를 설정하게 되면 문자열을 편집할 때마다 저 부분이 호출된다는 것을 알 수 있다.
테스트로 다음의 값을 입력했다.

```
여러 번 실행하다 보니 주소값이 계속 바뀌는 것을 볼 수 있었다. (ASLR이 적용되어 있는 걸까)
메모리 주소는 실행마다 달라지니 별도로 캡처하지 않을 것이고,
$Ordinal#1440 같은 상대주소의 함수들만 필요하다면 기록하겠다.
```
저 함수로 이동해 보자.
이동해서 살펴보면, 굉장히 코드가 긴 것을 볼 수 있다. 차근히 살펴보자.
먼저, name의 값을 점검한다.

name 조건 1: name의 길이는 4글자여야 한다.

이 반복문에서는 name의 알파벳을 하나씩 비교해서 a 보다 같거나 크거나 z 보다 같거나 작은지 검사한다.
name 조건 2: name은 소문자 알파벳이어야 한다.

여기 2중 반복문에서는 name에 겹치는 문자가 있는지 확인한다.
name 조건 3: name의 알파벳은 중복되지 않도록 한다.
이제는 number에 대해 점검한다.

number 조건 1: number는 11글자여야 한다.

number 조건 2: number 5번째는 '-'여야 한다.
참고로, 분석해 본 결과 &Ordinal#1440 함수는 다음의 역할을 한다.
* ecx에 문자열의 주소를 저장
* 인덱스를 스택에 push
* 1440 함수 호출
return 문자열의 해당 인덱스의 문자를 ax로 리턴
여기까지 검사를 하고 나면, 그 밑부분은 다음 사진처럼 복잡하고 귀찮게 돼있는 것을 볼 수 있다.

여기서부터는 일일이 캡처하지 않고, 분석한 내용을 정리해서 기록하겠다.
시리얼 번호 생성 과정
name의 4글자를 예시로 'name'이라고 하자.
시리얼 번호는 총 11글자로 _ _ _ _ _ - _ _ _ _ _ 형태이다.
시리얼 번호의 앞 5 번호는 name의 첫 두 글자 즉, 'na'로 만들어진다.
시리얼 번호의 뒤 5번호는 name의 뒤 두글자 즉, 'me'로 만들어진다.
생성과정은 다음과 같다. (조금 복잡하다)

origin1 = 첫 번째 글자 n, 세 번째 글자 m
ㄱ: origin1 & 1 + 5 (cl 레지스터 이용)
ㄴ: origin1 >> 1 & 1 + 5 (cl 레지스터 이용)
ㄷ: origin1 >> 2 & 1 + 5 (dl 레지스터 이용)
ㄹ: origin1 >> 3 & 1 + 5 (bl 레지스터 이용)
ㅁ: origin1 >> 4 & 1 + 5 (al 레지스터 이용)

origin2 = 두 번째 글자 a, 네 번째 글자 e
ㅂ: origin2 & 1 + 1 (cl 레지스터 이용)
ㅅ: origin2 >> 1 & 1 + 1 (cl 레지스터 이용)
ㅇ: None
ㅈ: origin2 >> 3 & 1 + 1 (dl 레지스터 이용)
ㅊ: origin2 >> 4 & 1 + 1 (al 레지스터 이용)
<시리얼 번호 앞 5글자>
n과 a를 사용해서 만든 ㄱ, ㄴ, ㄷ, ㄹ, ㅁ, ㅂ, ㅅ, ㅇ, ㅈ, ㅊ를 사용한다.
첫 번째 번호: ㄱ + (origin2 >> 2 & 1 + 1)
두 번째 번호: ㄹ + ㅈ
세 번째 번호: ㅊ + ㄴ
네 번째 번호: ㄷ + ㅂ
다섯 번째 번호: ㅁ + ㅅ
<시리얼 번호 뒤 5글자>
m과 e를 사용해서 만든 ㄱ, ㄴ, ㄷ, ㄹ, ㅁ, ㅂ, ㅅ, ㅇ, ㅈ, ㅊ를 사용한다.
첫 번째 번호: ㄱ + (origin2 >> 2 & 1 + 1)
두 번째 번호: ㄹ + ㅈ
세 번째 번호: ㄴ + ㅊ
네 번째 번호: ㅂ + ㄷ
다섯 번째 번호: ㅁ + ㅅ
위의 과정은 어셈블리어를 그대로 번역하여 해석한 것이다 보니 조금은 이해하기 난해하다.
그림을 그려서 생성과정을 조금 더 쉽게 설명해 보겠다.
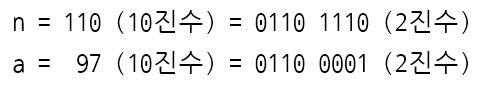

이 코드에서의 시리얼 생성 과정은 입력된 이름의 이진수 하위 5비트를 이용해서 생성하게 된다.
총 4글자의 이름이 입력되어야 하고,
앞 두 글자로 시리얼 앞 5글자를 생성하고,
뒤 두 글자로 시리얼 뒤 5글자를 생성한다.
두 글자에서 첫 번째 글자가 그림에서 윗부분의 이진수를 가리킨다.
두 글자에서 두 번째 글자가 그림에서 아랫부분의 이진수를 가리킨다.
각 몇 번째 비트가 몇 번째 시리얼 번호를 만드는 데 사용되는가는 그림을 참고하길 바란다.
윗 이진수의 비트와 아래 이진수의 비트를 더하게 되는데 이때,
윗 이진수에는 5를 더하여 더하고,
아래 아진수에는 1을 더하여 더하게 된다.
즉, 위 그림의 예제에서 더하여 보면
67786 이 되고,
이 숫자가 Input name에 'name' 문자열을 입력했을 때의 앞부분의 시리얼 번호가 되는 것이다.
뒷부분도 마찬가지로 구해보자.


뒤 시리얼 번호는 Input name에 'name' 문자열이 입력되었을 때,
87686이 된다.
결국 'name'에 대한 시리얼 번호는 67786-87686이 된다.

문제 풀이
어느 정도 분석이 끝났다.
이제 이를 이용해서 문제를 해결하면 된다.
readme에는 시리얼 번호가 76876-77776이었을 때의 name 값을 구하라고 하였다.
코드를 사용해서 구하도록 하겠다.
import copy
import re
def make_dic():
string = 'abcdefghijklmnopqrstuvwxyz'
name_dic = {}
for i in range(len(string)):
for j in range(len(string)):
si = string[i]
sj = string[j]
bi = format(ord(si), 'b').zfill(8)
bj = format(ord(sj), 'b').zfill(8)
name_dic[si+sj] = bi+bj
return name_dic
def extract_sum_bits(serial_string):
list_sum_bits = []
for serial in serial_string:
sum_bits = int(serial) - 6
list_sum_bits.append(sum_bits)
return list_sum_bits
def define_index(i):
if i == 0:
return 4, 2
elif i == 1:
return 1, 1
elif i == 2:
return 3, 0
elif i == 3:
return 2, 4
else: # i == 4
return 0, 3
def make_default_re(sum_two_letter_list):
re_list = [['.','.','.','.','.','.','.','.','.','.']]
for i, value in enumerate(sum_two_letter_list):
f_i, l_i = define_index(i)
if value == 0:
for re in re_list:
re[f_i] = '0'
re[l_i+5] = '0'
elif value == 2:
for re in re_list:
re[f_i] = '1'
re[l_i+5] = '1'
else:
re_list = aa(re_list, f_i, l_i)
re_string_list = []
for re in re_list:
re_string_list.append(''.join(re))
return re_string_list
def aa(re_list, f_i, l_i):
new_list = []
for re in re_list:
first = copy.deepcopy(re)
second = copy.deepcopy(re)
first[f_i] = '0'
first[l_i+5] = '1'
second[f_i] = '1'
second[l_i+5] = '0'
new_list.append(first)
new_list.append(second)
return new_list
def polish_re(re_list):
dotdotdot = '...'
new_re_list = []
for re in re_list:
new_re_list.append(dotdotdot + re[0:5] + dotdotdot + re[5:])
return new_re_list
def change_re_to_string(name_dict, re_list):
string_list = []
for pattern in re_list:
regex = re.compile(pattern)
string_list.append([key for key, value in name_dict.items() if regex.match(value)])
# print(pattern, string_list)
return string_list
def make_name(first_list, last_list):
init_name_list = []
for f in first_list:
if f == []:
continue
for l in last_list:
if l == []:
continue
init_name_list.append(f+l)
final_name_list = []
for name in init_name_list:
if len(set(name)) != 4:
continue
final_name_list.append(name)
return final_name_list
serial_number = '76876-77776'
name_dict = make_dic()
list_serial = serial_number.split('-')
first = list_serial[0]
last = list_serial[1]
sum_first_two_letter_list = extract_sum_bits(first)
sum_last_two_letter_list = extract_sum_bits(last)
# print(sum_first_two_letter_list)
# print(sum_last_two_letter_list)
first_re_list = polish_re(make_default_re(sum_first_two_letter_list))
last_re_list = polish_re(make_default_re(sum_last_two_letter_list))
# print(first_re_list)
# print(last_re_list)
first_name_list = change_re_to_string(name_dict, first_re_list)
last_name_list = change_re_to_string(name_dict, last_re_list)
# print(first_name_list)
# print(last_name_list)
print(make_name(sum(first_name_list, []), sum(last_name_list, [])))코드가 상당히 길고, 주석은 따로 달지 않았다.
결괏값은 다음과 같다.

여기 적혀있는 모든 값은 76876-77776 시리얼 값에 대해서 Correct! 문자열을 나오게 할 수 있는 값들이다.
하지만 readme에서 name의 마지막 글자가 p라고 했으므로 이중 p로 끝나는 name이 flag일 것이다.
p로 끝나는 값이 여러 개 있지만, 오직 하나만 정답인 것 같다.
코드가 꽤 긴데, 코드를 설명하는 글은 따로 적도록 하겠다.
2023.07.03 - [리버싱] - Position 파이썬 코드 해설
Position 파이썬 코드 해설
이번 글에서는 Position 파이썬 코드를 해설하겠다. Position 문제에 대해서는 다음 글을 참고하면 된다. 2023.07.03 - [리버싱] - Reversing.kr Position 문제 풀이 Reversing.kr Position 문제 풀이 주어지는 파일 Posi
hobak-gamja.tistory.com
'리버싱' 카테고리의 다른 글
| [Reversing.kr] Direct3D FPS 문제 풀이 (0) | 2023.07.14 |
|---|---|
| Position 파이썬 코드 해설 (0) | 2023.07.03 |
| Reversing.kr ImagePrc 문제 풀이 (0) | 2023.06.18 |
| Reversing.kr Replace 문제 풀이 (0) | 2023.06.16 |
| Reversing.kr Music Player 문제 풀이 (0) | 2023.06.15 |


